In 第一课 of SQL索引说明,我们学会了使用排序来加快数据检索. 而我们的查询在行排序后执行得更快, 排序包括至少读取每一行一次并移动它们. 这使得该方法比简单地按顺序读取整个表更慢,效率更低.
合乎逻辑的结论似乎是,我们应该维护排序的副本——我们将其正式称为SQL 索引,前缀为 IX_-给定表的. 然后,第一篇文章中的检索算法就适用了, 在开始之前,我们不需要对表进行排序.
让我们看一下这个想法的字面实现,同样使用Google Sheets. 我们的预订电子表格变成 五张纸的合集 包含相同的数据. 每张表格都是根据不同的列进行排序的.
这里的练习不像前一篇SQL索引教程文章那么严格,可以根据感觉而不是计时器和行数来完成. 有些练习看起来很相似,但这一次,我们将探索:
上一篇教程的重点是阅读, 但是在许多常见的实际数据动态中(包括我们的酒店预订),我们必须考虑索引对写入性能的影响, 用于插入新数据和更新现有数据.
感受一下使用排序表策略的SQL索引性能, 您的任务是删除客户端12的预订, 自2020年8月22日起, 在4号酒店. 请记住,您必须从表的所有副本中删除一行,并维护正确的排序.
完成? 很明显,保持表的多个排序副本的想法并不像看起来那么好. 如果你还有疑问, 您还可以尝试重新插入刚刚删除的预订或更改现有预订的日期.
而表的排序副本允许更快的检索, 正如我们刚才学到的, 数据修改是一场噩梦. 每当我们需要添加、删除或更新现有行时,我们都必须检索 所有 拷贝表,找到一行 和/或 应该添加或移动的位置,最后移动数据块.
这个表格 包含使用不同方法的索引. 索引行仍然按照特定的标准排序, 但是我们不把所有其他信息都放在下标行. 而不是, 我们只保留行地址,在H列中表示保留表本身的行的地址.
所有RDBMS实现都使用操作系统级的功能来使用物理地址快速找到磁盘上的块. 行地址通常由一个块地址加上行在块中的位置组成.
让我们做一些练习来了解这个索引设计是如何工作的.
与第一篇文章一样,您将模拟执行以下命令 SQL 查询:
SELECT *
从预订
WHERE ClientID = 12;
同样,有两种合理的方法. 第一个是简单地从预订表中读取所有行,并只获取符合条件的行:
对于reservation中的每一行
如果预订.ClientID = 12,写下reservation.*
第二种方法涉及从IX_ClientID表读取数据, 对于任何符合条件的物品, 根据rowAddress值在Reservation表中查找一行:
获取IX_ClientID中ClientID = 12的第一行
虽然IX_ClientID.ClientID = 12
取预订.* where rowAddress = IX_ClientID.rowAddress
写下预订.*
从IX_ClientID获取下一行
这里,表达式 获取第一行 由类似于前一篇文章中看到的循环实现:
重复
从IX_ClientID中获取下一行
Until ClientID >= 12
通过向下滑动直到找到行,您可以找到具有给定rowAddress的行, 或者在rowAddress列上使用过滤器.
如果只有少量预订需要退回, 使用索引的方法会更好. 然而, 要返回几百行,有时甚至只有几十行, 仅仅直接使用预订表就可以更快.
读取的数量取决于ClientID的值. 对于最大值, 你必须阅读整个索引, 而对于最低值, 它在索引的开头. 平均值是行数的一半.
我们稍后会回到这个部分,并给出一个有效的解决方案. 现在,让我们把重点放在部分上 后 你找到第一行符合我们的条件.
任务是使用新的指数设计计算2020年8月16日的入住次数.
选择计数(*)
从预订
WHERE DateFrom = TO_DATE('2020-08-16','YYYY-MM-DD');
使用适当索引的方法 计数 无论涉及多少行,都优于表扫描. 原因是我们根本不需要访问预订表——我们在索引本身中有我们需要的所有信息:
计数:= 0
获取第一行 IX_DateFrom where DateFrom >= '2020-08-16'
而 found and DateFrom < '2020-08-17'
Count:= Count + 1
从IX_DateFrom获取下一行
记下计数
该算法与使用排序表的算法基本相同. 然而, 索引行比表行短得多, 因此我们的RDBMS将不得不从磁盘读取更少的数据块.
让我们准备一份2020年8月13日和14日入住3号酒店的客人名单.
选择ClientID
从预订
WHERE 日期(之间))
TO_DATE (' 2020-08-13 ', ' YYYY-MM-DD ')
TO_DATE (' 2020-08-14 ', ' YYYY-MM-DD ')
),
HotelID = 3;
我们可以从预订表中读取所有行,也可以使用其中一个可用的索引. 在做了同样的练习之后,根据特定的标准对表进行排序, 我们发现索引 IX_HotelID_DateFrom 是最有效的.
从ix_hotelid_datefromwhere获取第一行
HotelID = 3和
日期:2020-08-13 - 2020-08-14
而 found and DateFrom < '2020-08-15' and IX_HotelID_DateFrom.HotelID = 3
取预订.* where rowAddress = IX_HotelID_DateFrom.rowAddress
写下预订.ClientID
从IX_HotelID_DateFrom获取下一行
我们访问这个表是因为 ClientID Value,我们要报告的客人名单只需要这个信息. 如果我们在SQL索引中包含该值,我们根本不需要访问表. 试着准备一个只从这样一个索引读取的列表, IX_HotelID_DateFrom_ClientID:
从IX_HotelID_DateFrom_ClientID where获取第一行
HotelID = 3和
日期:2020-08-13 - 2020-08-14
而 found and HotelID = 3和 DateFrom < '2020-08-15'
写下ClientID
从IX_HotelID_DateFrom_ClientID获取下一行
当索引包含查询执行所需的所有信息时,我们称索引为 涵盖了 查询.
一份客人的身份证清单对警察调查罪案是毫无用处的. 我们需要提供姓名:
选择c.列出
来自预订部
加入客户c ON或.ClientID = c.ClientID
在r.日期(之间)
To_date ('2020-08-13', ' yyyy-mm-dd ')和
TO_DATE (' 2020-08-14 ', ' YYYY-MM-DD ')
),
r.HotelID = 3;
提供一个列表,除了数据从 预订 表,我们还需要一个 客户 包含客人信息的表,可以在 这个谷歌表格.
这个练习与前一个类似,方法也是如此.
从IX_HotelID_DateFrom_ClientID where获取第一行
HotelID = 3和
日期:2020-08-13 - 2020-08-14
而 found and HotelID = 3和 DateFrom < '2020-08-15'
获取客户.* where ClientID = IX_HotelID_DateFrom_ClientID.ClientID
写下客户.列出
从IX_HotelID_DateFrom_ClientID获取下一行
表达式 获取客户.* where ClientID = IX_HotelID_DateFrom_ClientID.ClientID 可以通过表扫描或使用我们的索引来实现吗. 如果我们使用表扫描,对于每个 ClientID 从 而 循环时,我们平均要从 客户 表:
——使用表扫描从客户端获取行
重复
从客户端获取下一行
直到ClientID = IX_HotelID_DateFrom_ClientID.没有找到ClientID
如果发现
写下列出
到目前为止我们考虑的索引实现(我们称之为“扁平”索引实现)不会有太大帮助. 我们必须从索引中读取相同数量的行(尽管行更小), 然后跳到里面那一排 客户 使用 RowAddress:
——使用平索引从客户端获取行
重复
从客户_PK_Flat中获取下一行
Until ClientID >= IX_HotelID_DateFrom_ClientID.ClientID
如果发现
获取客户.* where rowAddress = 客户_PK_Flat.rowAddress
写下列出
注意:在这里, PK 指“主键”,我们将在本系列后面的文章中探讨这个术语.
有没有一种方法来完成这一点,而不必读取这么多行? 是的,这正是b树索引的作用.
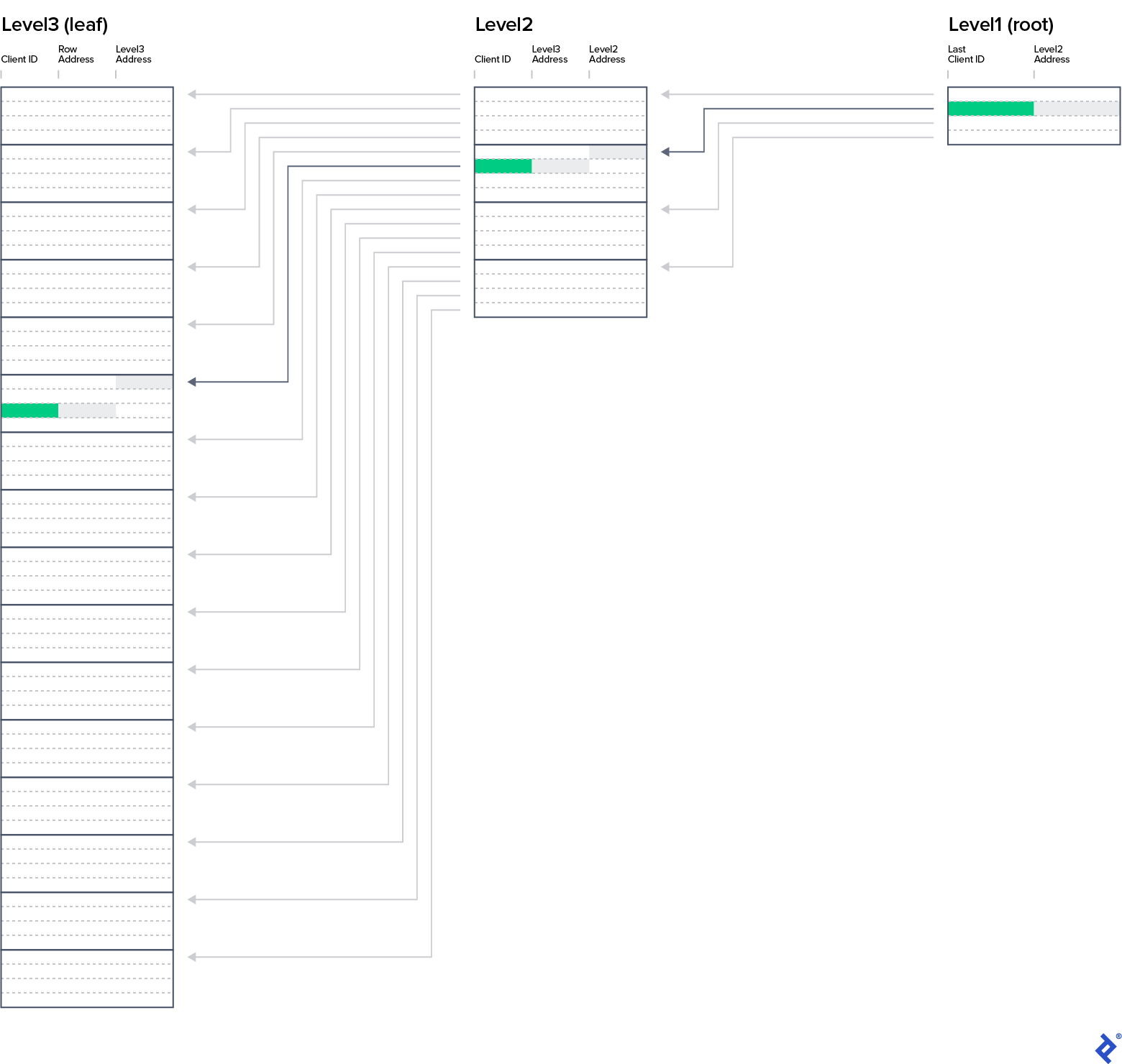
我们把这些行从 客户_PK_Flat 到四行块中,并创建一个包含最后一行值的列表 ClientID 从块和地址的块开始(列) IndexRowAddress). 生成的数据库索引数据结构—可以在客户_PK_2Levels表中找到. 尝试一下新的结构如何帮助你找到一个客户 ClientID of 28. 算法应该是这样的:
获取二级.*
循环
Leaf_address:= Level3Address
Exit when ClientID >= 28
从Level2中获取下一行
获取Level3.* where Level3Address = Leaf_address——3-21
循环
Client_address:= RowAddress
Exit when ClientID >= 28
从Level 3中获取下一行
获取客户.* where rowAddress = Client_address——42
写下客户.*
你可能知道我们可以再加一层. 级别1由四行组成,可以在IX_客户_PK选项卡中看到. 查找ClientID为28的客人的姓名, 您必须从主键结构中读取三个数据块(节点),每层读取一个,最后跳转到地址为42的客户行.
这个SQL索引的结构称为平衡树. 当从根节点到每个叶级节点的路径长度相同时,树是平衡的, 即所谓的b树深度. 在我们的例子中,深度是3.
从现在开始, 我们认为每个索引都具有b树结构, 即使我们的电子表格只包含叶级条目. 关于b树最重要的事实是:
现在, 警官正在寻找一份相应客人的名单, 到达日期, 以及A市所有酒店的名字.
SELECT
h.HotelName,
r.DateFrom作为checkkindate,
c.列出
来自预订部
加入客户c ON或.ClientID = c.ClientID
加入酒店集团.HotelID = h.HotelID
在r.日期(之间)
To_date ('2020-08-13', ' yyyy-mm-dd ')和
TO_DATE (' 2020-08-14 ', ' YYYY-MM-DD ')
),
h.城市= 'A';
如果我们用索引 IX_DateFrom_HotelID_ClientID, 然后对于日期范围内的每一行, 我们必须访问酒店表并检查酒店是否来自A市. 如果是,我们也必须访问客户表,以读取客户端的名称.
对于IX_DateFrom_HotelID_ClientID中的每一行
日期:2020-08-13 - 2020-08-14
对于来自酒店的每一行
HotelID = IX_DateFrom_HotelID_ClientID.HotelID
如果酒店.那么城市= A
获取客户.* where ClientID = IX_HotelID_DateFrom_ClientID.ClientID
写下来
酒店.HotelName,
IX_HotelID_DateFrom_ClientID.DateFrom,
客户.列出
使用 IX_HotelID_DateFrom_ClientID 给了我们一个更有效的执行计划.
对于hotel中City = 'A'的每一行
对于IX_HotelID_DateFrom_ClientID中的每一行
HotelID =酒店.HotelID和
日期:2020-08-13 - 2020-08-14
获取客户.* where ClientID = IX_HotelID_DateFrom_ClientID.ClientID
写下来
酒店.HotelName,
IX_HotelID_DateFrom_ClientID.DateFrom,
客户.列出
从 酒店 表中,我们找到了A市的所有酒店. 知道了这些酒店的ID,我们就可以从 IX_HotelID_DateFrom_ClientID 指数. 这种方式, 在b树叶子层找到每个酒店和日期的第一行之后, 我们没有看到A市以外的酒店的预订.

在这里, 我们可以看到,当我们有一个适合我们目标的数据库索引时, 额外的连接实际上可以使查询更快.
b树结构以及每当插入一行时如何更新它, 更新, 在我解释分区的动机及其影响时,将更详细地讨论或删除. 关键是,无论何时使用索引,我们都可以考虑快速执行此操作.
当涉及到索引和数据库, 在某种程度上,在SQL语言级别工作隐藏了实现细节. 这些练习旨在帮助您了解在使用不同的SQL索引时执行计划是如何工作的. 读完这篇文章后, 我希望您能够在给定可用索引和设计索引的情况下猜测出最佳执行计划,这些索引和设计索引将使查询尽可能快速和高效.
在本系列的下一部分中, 我们将使用和扩展新获得的技能来调查和理解 最常见的最佳实践和反模式 在SQL中使用索引. 我有一个好的和最佳实践的列表,我想在下一部分中讨论, 但是要使下一篇文章更符合您的需求和经验, 请随意 张贴你自己的问题,你希望看到回答.
In 最后一部分 of SQL索引说明, 我们还将学习表和索引分区, 使用它的正确和错误动机, 以及它对查询性能和数据库维护的影响.
SQL中的表是一个数据库对象,其中包含以行和列组织的数据. 在这方面,它类似于电子表格. 每行代表一个由列值组成的记录. 表定义包括每个列的名称和数据类型以及适用于表数据的约束.
SQL表可以有与之关联的索引. 索引的作用是支持快速的数据检索. 除此之外, 索引还用于强制惟一键约束和加速外键约束的评估.
布拉格,捷克共和国
2020年6月18日成为会员
世界级的文章,每周发一次.
世界级的文章,每周发一次.
